LISU: Low-light indoor scene understanding with joint learning of reflectance restoration
0. 写在前面
这篇文章开创性地研究了低光室内语义分割的课题,这个课题好像还挺少有人研究的。但是也有一定的意义,比如低光的室内导航,不知道这个方法能不能迁移到夜晚室外路面的分割,后期有时间笔者再实际的测试一下。
1. 论文基本信息
2. 论文主要内容
使用CNN的语义分割已经取得了很不错的成绩,但是当训练数据较少时,网络无法在光照变化下取得令人满意的分割结果。这篇论文,作者研究了在室内低光环境中的语义分割,并且提出了一个真实的和一个渲染的低光数据集用于评估结果。作者提出了一个用于低光分割的多任务网络 LISU,网络由两条分支组成,一条分支是语义分割分支,另一条分支是反射图修复分支。两条分支的深度特征级联起来以提升语义分割的结果。实验结果显示:语义信息可以帮助修复反射图,而修复的反射图更进一步帮助语义分割分支取得更好的效果。同时作者还尝试使用渲染数据进行模型预训练,并再次将最终的mIoU提升了7.2%。
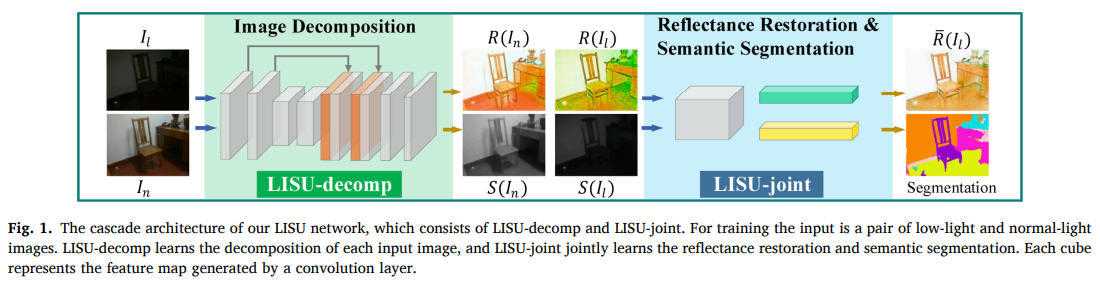
提出的LISU网络是一个级联网络,由LISU-decomp和LISU-joint组成。作者首先将一副图像通过LISU-decomp进行本征分解得到反射图和光照图。
直接在反射图上进行分割可以提升分割性能,因为反射图上没有光照的影响,像素颜色表达的是物体本身的颜色。根据Retinex理论,同一场景在不同光照下,反射图是不变的,只有光照图是不一样的,因此在理想情况下,一个物体在不同光照下的反射图上都是不变的,作者根据这一点决定在低光图像的反射图上进行语义分割。
作者首先利用自监督学习先训练了一个图像分解网络:输入一张图像,网络输出图像的反射图和光照图。随后将低光图像的光照图和低光图像的反射图一起输入进LISU-joint进行反射图修复和语义分割的联合学习。进行联合学习反射图修复的考虑是,因为低光图像分解得到的反射图质量特别差 (degraded reflectance map),损失了很多信息,因此作者希望修复反射图来得到更好的反射图特征。
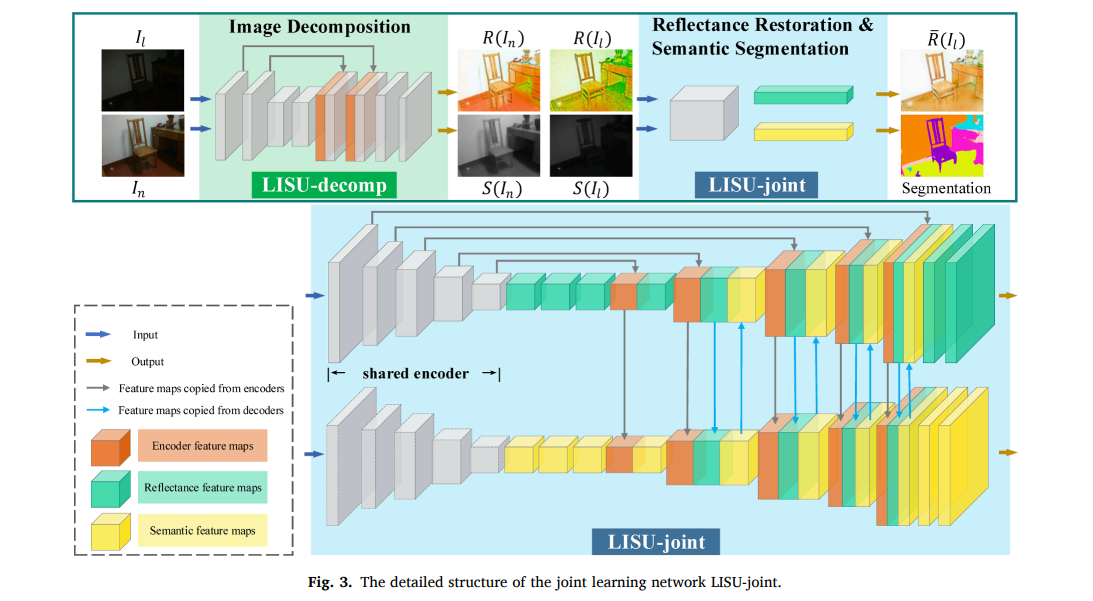
作者使用的网络是一个基于U-Net的多任务网络,网络共用一个encoder,但是两个不同的任务有两个不同的decoder学习。同时,两个解码器的特征被联结到一起进行特征的融合。
网络训练方面,作者采用反射图恢复损失与交叉熵损失组合的方式进行。

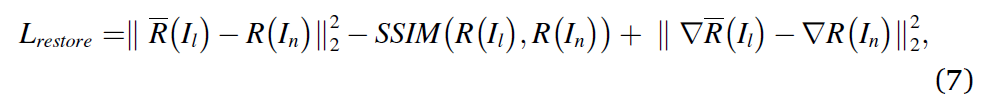

3. 论文源码解析
作者模型的实现采用编码器和解码器分开的方式进行,最终实现了两个Class。官方开源的仓库中结构非常清晰,编码器解码器的组合是在模型训练与验证的脚本main.py内实现的。
"""
@FileName: models.py
@Time : 7/16/2020
@Author : Ning Zhang
@GitHub: https://github.com/noahzn
"""
import torch
import torch.nn as nn
import torch.nn.functional as F
class LISU_DECOMP(nn.Module):
def __init__(self):
super().__init__()
self.conv_1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=3, stride=1, padding=1)
self.conv_2 = nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=1)
self.conv_3 = nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=2, padding=1)
self.conv_4 = nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=1)
self.conv_5 = nn.ConvTranspose2d(in_channels=128, out_channels=64, kernel_size=3, stride=2, padding=1,
output_padding=1)
self.conv_6 = nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3, stride=1, padding=1)
self.conv_7 = nn.Conv2d(in_channels=128, out_channels=64, kernel_size=3, stride=1, padding=1)
self.conv_8 = nn.Conv2d(in_channels=64, out_channels=4, kernel_size=1, stride=1, padding=0)
def forward(self, img):
c1 = self.conv_1(img)
c2 = F.relu(self.conv_2(c1))
c3 = F.relu(self.conv_3(c2))
c4 = F.relu(self.conv_4(c3))
c5 = F.relu(self.conv_5(c4))
c6 = F.relu(self.conv_6(torch.cat((c2, c5), dim=1)))
c7 = self.conv_7(torch.cat((c1, c6), dim=1))
c8 = self.conv_8(c7)
c9 = torch.sigmoid(c8)
reflectance, illumination = c9[:, :3, :, :], c9[:, 3:4, :, :]
return illumination, reflectance
class LISU_JOINT(nn.Module):
def __init__(self):
super().__init__()
self.in_channels = 4
# Encoder layers
self.conv1 = nn.Sequential(
nn.Conv2d(4, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU()
)
self.conv2 = nn.Sequential(
nn.Conv2d(32, 64, 3, 2, 1),
nn.BatchNorm2d(64),
nn.ReLU()
)
self.conv3 = nn.Sequential(
nn.Conv2d(64, 128, 3, 2, 1),
nn.BatchNorm2d(128),
nn.ReLU()
)
self.conv4 = nn.Sequential(
nn.Conv2d(128, 256, 3, 2, 1),
nn.BatchNorm2d(256),
nn.ReLU()
)
self.conv5 = nn.Sequential(
nn.Conv2d(256, 256, 3, 2, 1),
nn.BatchNorm2d(256),
nn.ReLU()
)
# decoder
self.mid_r = nn.Sequential(
nn.Conv2d(256, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(), )
self.mid_s = nn.Sequential(
nn.Conv2d(256, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Conv2d(256, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(), )
self.deconv4_r = nn.Sequential(
nn.Conv2d(512, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Upsample(scale_factor=2, mode='bilinear'),
)
self.deconv3_r = nn.Sequential(
nn.Conv2d(768, 128, 3, 1, 1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Upsample(scale_factor=2, mode='bilinear'),
)
self.deconv2_r = nn.Sequential(
nn.Conv2d(384, 64, 3, 1, 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Upsample(scale_factor=2, mode='bilinear'),
)
self.deconv1_r = nn.Sequential(
nn.Conv2d(192, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Upsample(scale_factor=2, mode='bilinear'), )
self.deconv4_s = nn.Sequential(
nn.Conv2d(512, 256, 3, 1, 1),
nn.BatchNorm2d(256),
nn.ReLU(),
nn.Upsample(scale_factor=2, mode='bilinear'),
)
self.deconv3_s = nn.Sequential(
nn.Conv2d(768, 128, 3, 1, 1),
nn.BatchNorm2d(128),
nn.ReLU(),
nn.Upsample(scale_factor=2, mode='bilinear'),
)
self.deconv2_s = nn.Sequential(
nn.Conv2d(384, 64, 3, 1, 1),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.Upsample(scale_factor=2, mode='bilinear'),
)
self.deconv1_s = nn.Sequential(
nn.Conv2d(192, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Upsample(scale_factor=2, mode='bilinear'), )
self.out_r = nn.Sequential(
nn.Conv2d(96, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 3, 3, 1, 1),
)
self.out_s = nn.Sequential(
nn.Conv2d(96, 32, 3, 1, 1),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.Conv2d(32, 14, 3, 1, 1),
)
def forward(self, x):
x1 = self.conv1(x)
# 16 x 240 x 320
x2 = self.conv2(x1)
# 32 x 120 x 160
x3 = self.conv3(x2)
# 64 x 60 x 80
x4 = self.conv4(x3)
# 128 x 30 x 40
x5 = self.conv5(x4)
# 256 x 15 x 20
xmid_r = torch.cat((self.mid_r(x5), x5), dim=1)
xmid_s = torch.cat((self.mid_s(x5), x5), dim=1)
# 512 x 15 x 20
x4d_r = self.deconv4_r(xmid_r)
x4d_s = self.deconv4_s(xmid_s)
x3d_r = self.deconv3_r(torch.cat([x4d_r] + [x4d_s] + [x4], dim=1))
x3d_s = self.deconv3_s(torch.cat([x4d_s] + [x4d_r] + [x4], dim=1))
x2d_r = self.deconv2_r(torch.cat([x3d_r] + [x3d_s] + [x3], dim=1))
x2d_s = self.deconv2_s(torch.cat([x3d_s] + [x3d_r] + [x3], dim=1))
x1d_r = self.deconv1_r(torch.cat([x2d_r] + [x2d_s] + [x2], dim=1))
x1d_s = self.deconv1_s(torch.cat([x2d_s] + [x2d_r] + [x2], dim=1))
out_r = torch.sigmoid(self.out_r(torch.cat([x1d_r] + [x1d_s] + [x1], dim=1)))
out_s = self.out_s(torch.cat([x1d_s] + [x1d_r] + [x1], dim=1))
return out_r, out_s
