0. 写在前面
这篇文章的核心目标是实现移动端实时运行的骨干网络,但笔者感觉其工作中心在对已有创新的组合测验上,且在端载板卡上的精度降幅有些明显。
1. 论文基本信息
2. 论文主要内容
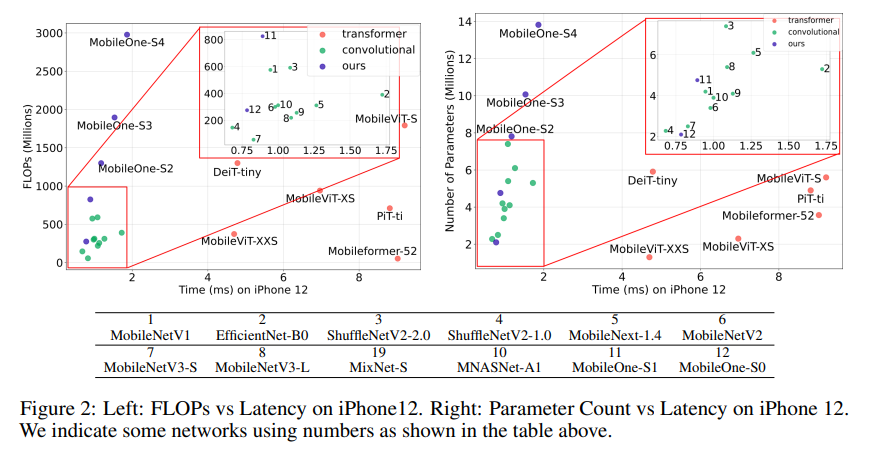
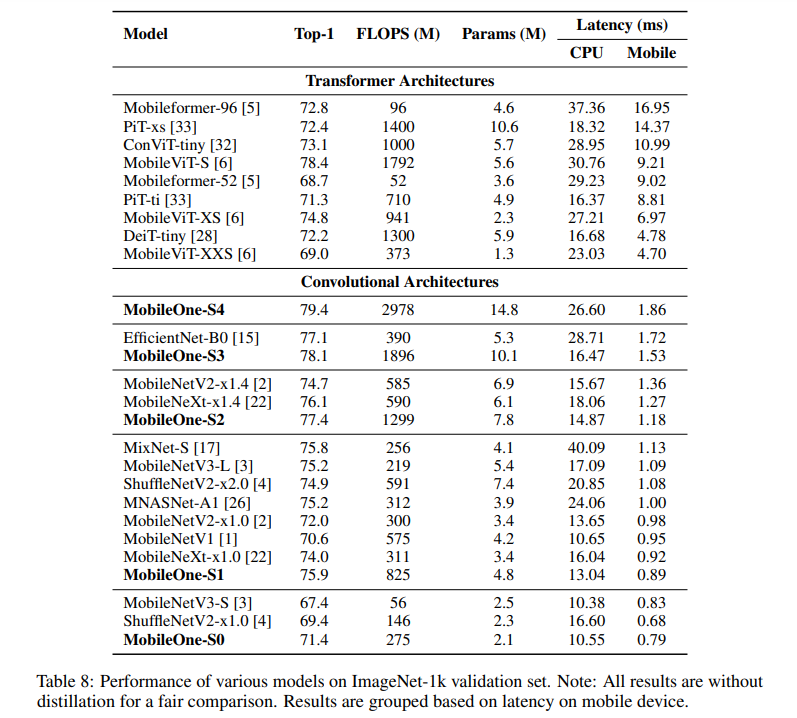
用于移动设备的高效神经网络骨干通常针对 FLOP 或参数计数等指标进行优化。然而,当部署在移动设备上时,这些指标可能与网络的延迟没有很好的相关性。因此,作者通过在移动设备上部署多个移动友好网络来对不同指标进行广泛分析。作者识别和分析最近高效神经网络中的架构和优化瓶颈,并提供缓解这些瓶颈的方法。为此,他们设计了一个高效的骨干 MobileOne,其变体在 iPhone12 上的推理时间低于 1 毫秒,在 ImageNet 上的 top-1 准确率为 75.9%。作者展示了 MobileOne 在高效架构中实现了SOTA性能,同时在移动设备上速度提高了许多倍。他们最好的模型在 ImageNet 上获得了与 MobileFormer 相似的性能,同时速度提高了 38 倍。作者的模型在 ImageNet 上的 top-1 准确率比 EfficientNet 在相似的延迟下高 2.3%。此外,作者还展示了他们的模型可以推广到多个任务——图像分类、目标检测和语义分割,与部署在移动设备上的现有高效架构相比,延迟和准确度显著提高。
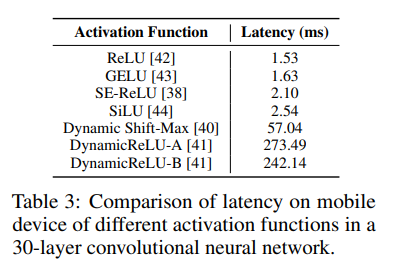
激活函数。为了分析激活函数对延迟的影响,作者构建了一个 30 层的卷积神经网络,并使用不同的激活函数在 iPhone12 上对其进行基准测试,这些激活函数通常用于高效的 CNN 骨干网络。下表中的所有模型除了激活函数之外都具有相同的架构,但它们的延迟却截然不同。这可以归因于同步成本,其主要是由最近引入的激活函数(如 SE-ReLU [38]、Dynamic Shift-Max [40] 和 DynamicReLUs [41])引起的。 DynamicReLU 和 Dynamic Shift-Max 在 MicroNet [40] 等极低 FLOP 模型中显示出显著改进,使用这些激活函数的延迟成本可能很高。将来,可以为这些激活函数提供硬件加速,但好处将仅限于实现它们的平台。因此,作者在 MobileOne 中仅使用 ReLU 激活函数。
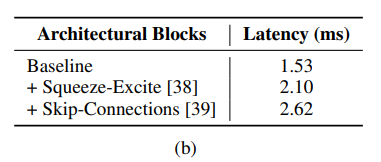
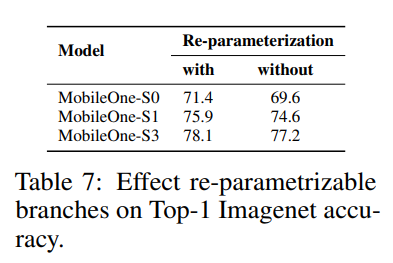
架构块。 影响运行时性能的两个关键因素是内存访问成本和并行度 [4]。在多分支架构中,内存访问成本显著增加,因为必须存储来自每个分支的激活函数来计算图中的下一个张量。如果网络的分支数量较少,则可以避免此类内存瓶颈。由于同步成本,强制同步的架构块(如 Squeeze-Excite 块 [38] 中使用的全局池化操作)也会影响整体运行时间。为了演示内存访问成本和同步成本等隐藏成本,作者在 30 层卷积神经网络中过度使用跳跃连接和Squeeze-Exite块。在下表中,作者展示了这些选择中的每一个如何导致延迟。因此,他们采用了在推理时没有分支的架构,从而降低了内存访问成本。此外,作者将 Squeeze-Excite 块的使用限制在他们最大的变体中,以提高准确性。
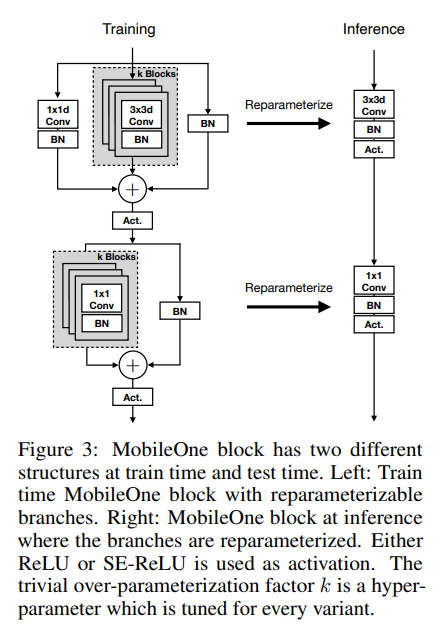
基于作者对不同设计选择的评估,他们开发了 MobileOne 架构。与之前关于结构重新参数化的工作一样 [34、12、13、14],MobileOne 的训练时间和推理时间架构是不同的。
MobileOne 块。 MobileOne 块类似于 [34, 12, 13, 14] 中介绍的块,不同之处在于作者的块是为卷积层设计的,这些卷积层被分解为深度层和点层。此外,他们引入了简单的过度参数化分支,这些分支提供了进一步的收益,具体的结构如下图所示。
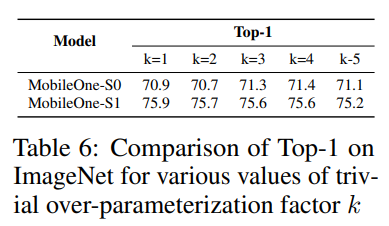
为了更好地理解使用训练时间可重新参数化分支的改进,作者通过删除训练时间可重新参数化分支(参见下表)来对 MobileOne 模型的不同版本进行消融研究,同时保持所有其他训练参数与之前描述的相同。
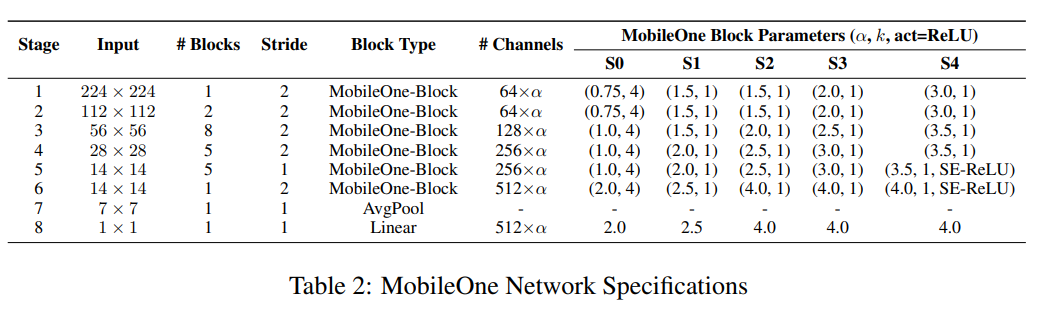
模型缩放。最近的工作缩放模型大小,如宽度、深度和分辨率以提高性能 [15, 45]。 MobileOne 与 MobileNet-V2 具有相似的深度缩放,即使用较浅的早期阶段,其中输入分辨率较大,因为这些层与在较小输入分辨率下运行的后期阶段相比要慢得多。
与大型模型相反,小型模型需要较少的正则化来对抗过拟合。正如 [46] 所证明的那样,在训练的早期阶段进行权重衰减是很重要的。作者发现,在训练过程中对权重衰减正则化所产生的损失进行退火,而不是像 [46] 中研究的那样完全消除权重衰减正则化更有效。在作者所有的实验中,他们使用余弦调度[47]作为学习率。因此,作者只需使用相同的时间表来退火权重衰减系数。

3. 论文源码解析
官方开源的仓库中只含有模型文件不包含损失函数、训练与测试脚本,其他第三方复现的仓库中虽然有相关脚本,但是在训练效果上目前还未得到验证,本次只对模型设计本身进行分析。
#
# For licensing see accompanying LICENSE file.
# Copyright (C) 2022 Apple Inc. All Rights Reserved.
#
from typing import Optional, List, Tuple
import copy
import torch
import torch.nn as nn
import torch.nn.functional as F
__all__ = ['MobileOne', 'mobileone', 'reparameterize_model']
class SEBlock(nn.Module):
""" Squeeze and Excite module.
Pytorch implementation of `Squeeze-and-Excitation Networks` -
https://arxiv.org/pdf/1709.01507.pdf
"""
def __init__(self,
in_channels: int,
rd_ratio: float = 0.0625) -> None:
""" Construct a Squeeze and Excite Module.
:param in_channels: Number of input channels.
:param rd_ratio: Input channel reduction ratio.
"""
super(SEBlock, self).__init__()
self.reduce = nn.Conv2d(in_channels=in_channels,
out_channels=int(in_channels * rd_ratio),
kernel_size=1,
stride=1,
bias=True)
self.expand = nn.Conv2d(in_channels=int(in_channels * rd_ratio),
out_channels=in_channels,
kernel_size=1,
stride=1,
bias=True)
def forward(self, inputs: torch.Tensor) -> torch.Tensor:
""" Apply forward pass. """
b, c, h, w = inputs.size()
x = F.avg_pool2d(inputs, kernel_size=[h, w])
x = self.reduce(x)
x = F.relu(x)
x = self.expand(x)
x = torch.sigmoid(x)
x = x.view(-1, c, 1, 1)
return inputs * x
class MobileOneBlock(nn.Module):
""" MobileOne building block.
This block has a multi-branched architecture at train-time
and plain-CNN style architecture at inference time
For more details, please refer to our paper:
`An Improved One millisecond Mobile Backbone` -
https://arxiv.org/pdf/2206.04040.pdf
"""
def __init__(self,
in_channels: int,
out_channels: int,
kernel_size: int,
stride: int = 1,
padding: int = 0,
dilation: int = 1,
groups: int = 1,
inference_mode: bool = False,
use_se: bool = False,
num_conv_branches: int = 1) -> None:
""" Construct a MobileOneBlock module.
:param in_channels: Number of channels in the input.
:param out_channels: Number of channels produced by the block.
:param kernel_size: Size of the convolution kernel.
:param stride: Stride size.
:param padding: Zero-padding size.
:param dilation: Kernel dilation factor.
:param groups: Group number.
:param inference_mode: If True, instantiates model in inference mode.
:param use_se: Whether to use SE-ReLU activations.
:param num_conv_branches: Number of linear conv branches.
"""
super(MobileOneBlock, self).__init__()
self.inference_mode = inference_mode
self.groups = groups
self.stride = stride
self.kernel_size = kernel_size
self.in_channels = in_channels
self.out_channels = out_channels
self.num_conv_branches = num_conv_branches
# Check if SE-ReLU is requested
if use_se:
self.se = SEBlock(out_channels)
else:
self.se = nn.Identity()
self.activation = nn.ReLU()
if inference_mode:
self.reparam_conv = nn.Conv2d(in_channels=in_channels,
out_channels=out_channels,
kernel_size=kernel_size,
stride=stride,
padding=padding,
dilation=dilation,
groups=groups,
bias=True)
else:
# Re-parameterizable skip connection
self.rbr_skip = nn.BatchNorm2d(num_features=in_channels) \
if out_channels == in_channels and stride == 1 else None
# Re-parameterizable conv branches
rbr_conv = list()
for _ in range(self.num_conv_branches):
rbr_conv.append(self._conv_bn(kernel_size=kernel_size,
padding=padding))
self.rbr_conv = nn.ModuleList(rbr_conv)
# Re-parameterizable scale branch
self.rbr_scale = None
if kernel_size > 1:
self.rbr_scale = self._conv_bn(kernel_size=1,
padding=0)
def forward(self, x: torch.Tensor) -> torch.Tensor:
""" Apply forward pass. """
# Inference mode forward pass.
if self.inference_mode:
return self.activation(self.se(self.reparam_conv(x)))
# Multi-branched train-time forward pass.
# Skip branch output
identity_out = 0
if self.rbr_skip is not None:
identity_out = self.rbr_skip(x)
# Scale branch output
scale_out = 0
if self.rbr_scale is not None:
scale_out = self.rbr_scale(x)
# Other branches
out = scale_out + identity_out
for ix in range(self.num_conv_branches):
out += self.rbr_conv[ix](x)
return self.activation(self.se(out))
def reparameterize(self):
""" Following works like `RepVGG: Making VGG-style ConvNets Great Again` -
https://arxiv.org/pdf/2101.03697.pdf. We re-parameterize multi-branched
architecture used at training time to obtain a plain CNN-like structure
for inference.
"""
if self.inference_mode:
return
kernel, bias = self._get_kernel_bias()
self.reparam_conv = nn.Conv2d(in_channels=self.rbr_conv[0].conv.in_channels,
out_channels=self.rbr_conv[0].conv.out_channels,
kernel_size=self.rbr_conv[0].conv.kernel_size,
stride=self.rbr_conv[0].conv.stride,
padding=self.rbr_conv[0].conv.padding,
dilation=self.rbr_conv[0].conv.dilation,
groups=self.rbr_conv[0].conv.groups,
bias=True)
self.reparam_conv.weight.data = kernel
self.reparam_conv.bias.data = bias
# Delete un-used branches
for para in self.parameters():
para.detach_()
self.__delattr__('rbr_conv')
self.__delattr__('rbr_scale')
if hasattr(self, 'rbr_skip'):
self.__delattr__('rbr_skip')
self.inference_mode = True
def _get_kernel_bias(self) -> Tuple[torch.Tensor, torch.Tensor]:
""" Method to obtain re-parameterized kernel and bias.
Reference: https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py#L83
:return: Tuple of (kernel, bias) after fusing branches.
"""
# get weights and bias of scale branch
kernel_scale = 0
bias_scale = 0
if self.rbr_scale is not None:
kernel_scale, bias_scale = self._fuse_bn_tensor(self.rbr_scale)
# Pad scale branch kernel to match conv branch kernel size.
pad = self.kernel_size // 2
kernel_scale = torch.nn.functional.pad(kernel_scale,
[pad, pad, pad, pad])
# get weights and bias of skip branch
kernel_identity = 0
bias_identity = 0
if self.rbr_skip is not None:
kernel_identity, bias_identity = self._fuse_bn_tensor(self.rbr_skip)
# get weights and bias of conv branches
kernel_conv = 0
bias_conv = 0
for ix in range(self.num_conv_branches):
_kernel, _bias = self._fuse_bn_tensor(self.rbr_conv[ix])
kernel_conv += _kernel
bias_conv += _bias
kernel_final = kernel_conv + kernel_scale + kernel_identity
bias_final = bias_conv + bias_scale + bias_identity
return kernel_final, bias_final
def _fuse_bn_tensor(self, branch) -> Tuple[torch.Tensor, torch.Tensor]:
""" Method to fuse batchnorm layer with preceeding conv layer.
Reference: https://github.com/DingXiaoH/RepVGG/blob/main/repvgg.py#L95
:param branch:
:return: Tuple of (kernel, bias) after fusing batchnorm.
"""
if isinstance(branch, nn.Sequential):
kernel = branch.conv.weight
running_mean = branch.bn.running_mean
running_var = branch.bn.running_var
gamma = branch.bn.weight
beta = branch.bn.bias
eps = branch.bn.eps
else:
assert isinstance(branch, nn.BatchNorm2d)
if not hasattr(self, 'id_tensor'):
input_dim = self.in_channels // self.groups
kernel_value = torch.zeros((self.in_channels,
input_dim,
self.kernel_size,
self.kernel_size),
dtype=branch.weight.dtype,
device=branch.weight.device)
for i in range(self.in_channels):
kernel_value[i, i % input_dim,
self.kernel_size // 2,
self.kernel_size // 2] = 1
self.id_tensor = kernel_value
kernel = self.id_tensor
running_mean = branch.running_mean
running_var = branch.running_var
gamma = branch.weight
beta = branch.bias
eps = branch.eps
std = (running_var + eps).sqrt()
t = (gamma / std).reshape(-1, 1, 1, 1)
return kernel * t, beta - running_mean * gamma / std
def _conv_bn(self,
kernel_size: int,
padding: int) -> nn.Sequential:
""" Helper method to construct conv-batchnorm layers.
:param kernel_size: Size of the convolution kernel.
:param padding: Zero-padding size.
:return: Conv-BN module.
"""
mod_list = nn.Sequential()
mod_list.add_module('conv', nn.Conv2d(in_channels=self.in_channels,
out_channels=self.out_channels,
kernel_size=kernel_size,
stride=self.stride,
padding=padding,
groups=self.groups,
bias=False))
mod_list.add_module('bn', nn.BatchNorm2d(num_features=self.out_channels))
return mod_list
class MobileOne(nn.Module):
""" MobileOne Model
Pytorch implementation of `An Improved One millisecond Mobile Backbone` -
https://arxiv.org/pdf/2206.04040.pdf
"""
def __init__(self,
num_blocks_per_stage: List[int] = [2, 8, 10, 1],
num_classes: int = 1000,
width_multipliers: Optional[List[float]] = None,
inference_mode: bool = False,
use_se: bool = False,
num_conv_branches: int = 1) -> None:
""" Construct MobileOne model.
:param num_blocks_per_stage: List of number of blocks per stage.
:param num_classes: Number of classes in the dataset.
:param width_multipliers: List of width multiplier for blocks in a stage.
:param inference_mode: If True, instantiates model in inference mode.
:param use_se: Whether to use SE-ReLU activations.
:param num_conv_branches: Number of linear conv branches.
"""
super().__init__()
assert len(width_multipliers) == 4
self.inference_mode = inference_mode
self.in_planes = min(64, int(64 * width_multipliers[0]))
self.use_se = use_se
self.num_conv_branches = num_conv_branches
# Build stages
self.stage0 = MobileOneBlock(in_channels=3, out_channels=self.in_planes,
kernel_size=3, stride=2, padding=1,
inference_mode=self.inference_mode)
self.cur_layer_idx = 1
self.stage1 = self._make_stage(int(64 * width_multipliers[0]), num_blocks_per_stage[0],
num_se_blocks=0)
self.stage2 = self._make_stage(int(128 * width_multipliers[1]), num_blocks_per_stage[1],
num_se_blocks=0)
self.stage3 = self._make_stage(int(256 * width_multipliers[2]), num_blocks_per_stage[2],
num_se_blocks=int(num_blocks_per_stage[2] // 2) if use_se else 0)
self.stage4 = self._make_stage(int(512 * width_multipliers[3]), num_blocks_per_stage[3],
num_se_blocks=num_blocks_per_stage[3] if use_se else 0)
self.gap = nn.AdaptiveAvgPool2d(output_size=1)
self.linear = nn.Linear(int(512 * width_multipliers[3]), num_classes)
def _make_stage(self,
planes: int,
num_blocks: int,
num_se_blocks: int) -> nn.Sequential:
""" Build a stage of MobileOne model.
:param planes: Number of output channels.
:param num_blocks: Number of blocks in this stage.
:param num_se_blocks: Number of SE blocks in this stage.
:return: A stage of MobileOne model.
"""
# Get strides for all layers
strides = [2] + [1]*(num_blocks-1)
blocks = []
for ix, stride in enumerate(strides):
use_se = False
if num_se_blocks > num_blocks:
raise ValueError("Number of SE blocks cannot "
"exceed number of layers.")
if ix >= (num_blocks - num_se_blocks):
use_se = True
# Depthwise conv
blocks.append(MobileOneBlock(in_channels=self.in_planes,
out_channels=self.in_planes,
kernel_size=3,
stride=stride,
padding=1,
groups=self.in_planes,
inference_mode=self.inference_mode,
use_se=use_se,
num_conv_branches=self.num_conv_branches))
# Pointwise conv
blocks.append(MobileOneBlock(in_channels=self.in_planes,
out_channels=planes,
kernel_size=1,
stride=1,
padding=0,
groups=1,
inference_mode=self.inference_mode,
use_se=use_se,
num_conv_branches=self.num_conv_branches))
self.in_planes = planes
self.cur_layer_idx += 1
return nn.Sequential(*blocks)
def forward(self, x: torch.Tensor) -> torch.Tensor:
""" Apply forward pass. """
x = self.stage0(x)
x = self.stage1(x)
x = self.stage2(x)
x = self.stage3(x)
x = self.stage4(x)
x = self.gap(x)
x = x.view(x.size(0), -1)
x = self.linear(x)
return x
PARAMS = {
"s0": {"width_multipliers": (0.75, 1.0, 1.0, 2.0),
"num_conv_branches": 4},
"s1": {"width_multipliers": (1.5, 1.5, 2.0, 2.5)},
"s2": {"width_multipliers": (1.5, 2.0, 2.5, 4.0)},
"s3": {"width_multipliers": (2.0, 2.5, 3.0, 4.0)},
"s4": {"width_multipliers": (3.0, 3.5, 3.5, 4.0),
"use_se": True},
}
def mobileone(num_classes: int = 1000, inference_mode: bool = False,
variant: str = "s0") -> nn.Module:
"""Get MobileOne model.
:param num_classes: Number of classes in the dataset.
:param inference_mode: If True, instantiates model in inference mode.
:param variant: Which type of model to generate.
:return: MobileOne model. """
variant_params = PARAMS[variant]
return MobileOne(num_classes=num_classes, inference_mode=inference_mode,
**variant_params)
def reparameterize_model(model: torch.nn.Module) -> nn.Module:
""" Method returns a model where a multi-branched structure
used in training is re-parameterized into a single branch
for inference.
:param model: MobileOne model in train mode.
:return: MobileOne model in inference mode.
"""
# Avoid editing original graph
model = copy.deepcopy(model)
for module in model.modules():
if hasattr(module, 'reparameterize'):
module.reparameterize()
return model
