NeW CRFs: Neural Window Fully-connected CRFs for Monocular Depth Estimation
0. 写在前面
这篇文章开创性地将深度学习方法与条件随机场(CRFs)相结合解决单目深度估计的问题,相较于传统简单粗暴的用复杂网络直接回归深度图而言,这篇文章提出了一个全新的思路,值得在此方面开展深入的研究工作。
1. 论文基本信息
2. 论文主要内容
单目深度估计是从单张RGB图预测场景深度,是一个很具有挑战性的任务。现在做这个任务的方法大都是设计越来越复杂的网络来简单粗暴地回归深度图,但本文作者采取了一个更具可解释性的方案,就是使用优化方法中的条件随机场(CRFs)。由于CRFs的计算量很大,通常只会用于计算相邻节点的能量,而很难用于计算整个图模型中所有节点之间的能量。为了借助这种全连接CRFs的强大表征力,他们采取了一种折中的方法,即将整个图模型划分为一个个小窗口,在每个窗口里面进行全连接CRFs的计算,这样就可以大大减少计算量,使全连接CRFs在深度估计这一任务上成为了可能。同时,为了更好地在节点之间进行信息传递,他们利用多头注意力机制计算了多头能量函数,然后用网络将这个能量函数优化到一个精确的深度图。
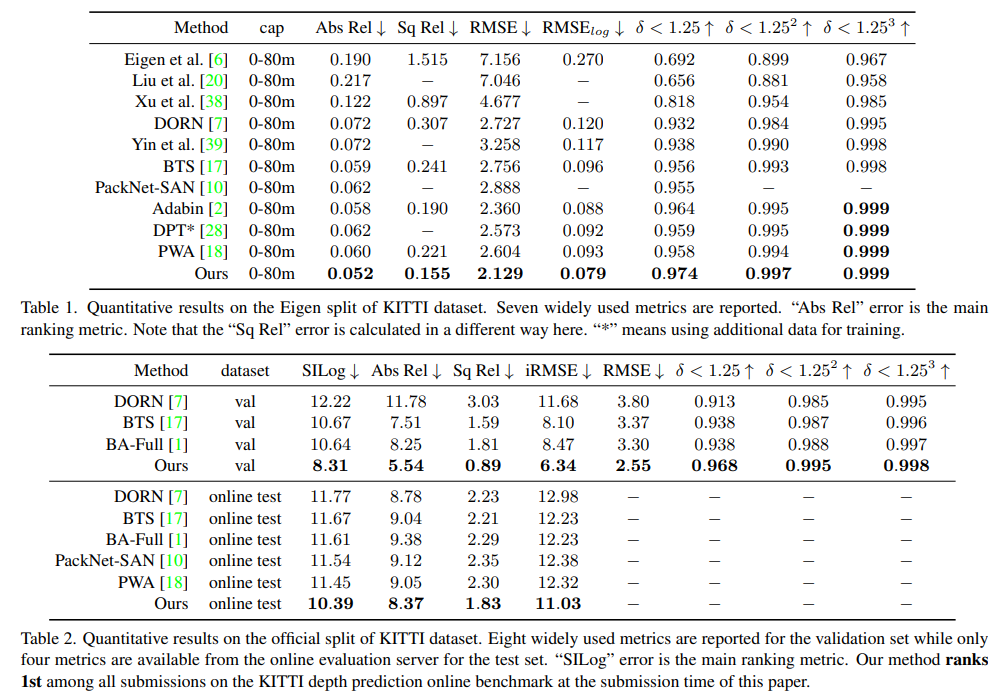
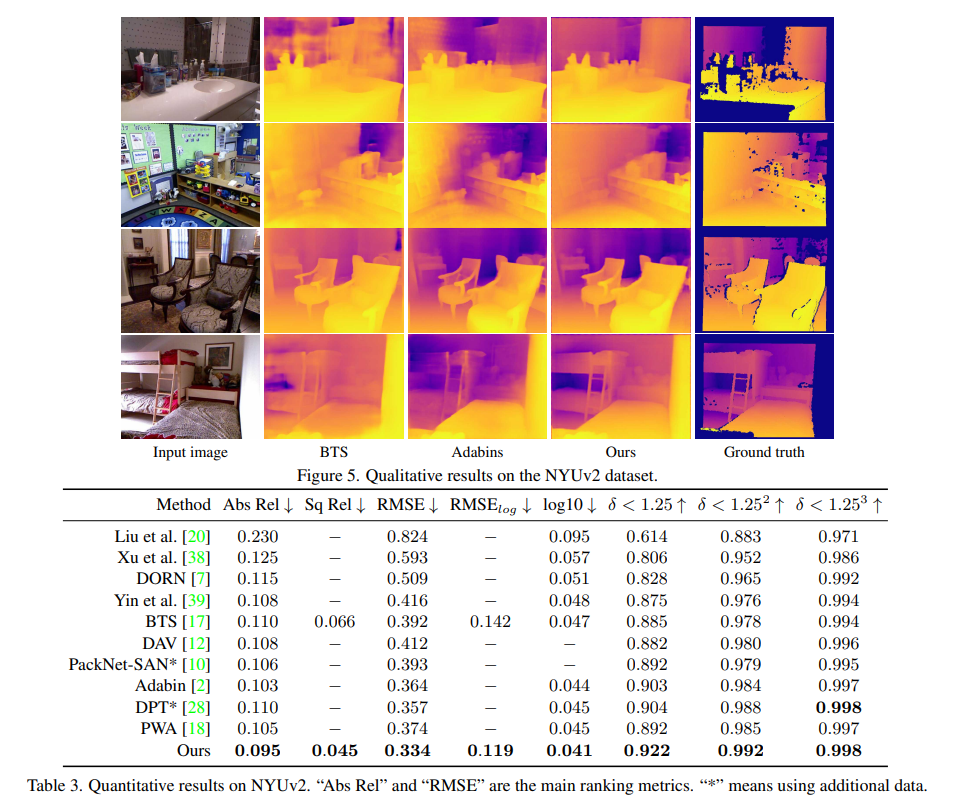
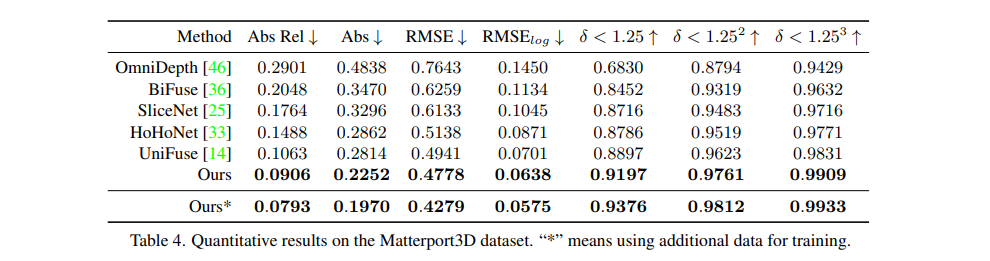
基于此,作者用视觉transformer作为encoder,神经窗口全连接条件随机场作为decoder,构建了一个bottom-up-top-down的网络架构,这个网络在KITTI、NYUv2上都取得了SOTA的性能,同时可以应用于全景图深度估计任务,在MatterPort3D上也取得了SOTA的性能。
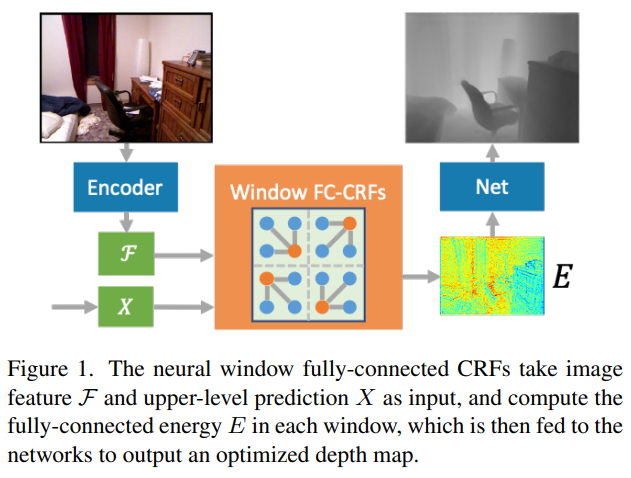
与普通的条件随机场相比,全连接条件随机场可以建立一个图模型中每个节点之间的关联,从而更好地进行特征提取和信息传递,强大的多。所以在本项工作中,作者希望能够使用全连接条件随机场,但是,全连接条件随机场的计算量大到惊人,在一个高分辨率的图中是很难做到的。另一方面,他们考虑到,其实在进行深度估计的时候,当前节点的深度值受很远的像素影响较小,也就是说,并不那么需要建立起当前节点跟距离很远的节点之间的信息传递。
于是,作者提出了一个基于窗口的全连接条件随机场。我们将一整个图模型划分为多个基于patch的窗口,每个窗口有 N×N 个图像patch,每个patch作为一个节点,由 你n×n 个像素构成。在每个窗口中,所有的节点都互相连接,也就是全连接,而不同窗口之间没有连接。
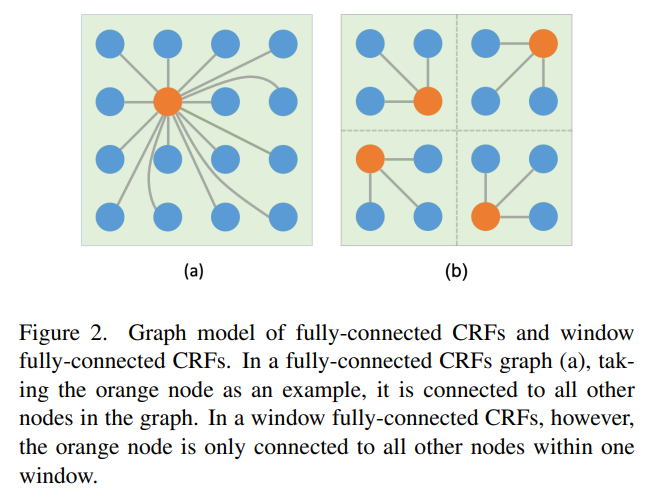
这样一来,计算量就可以大大减少。以一张含有 h×h 个patch的图片为例,全连接条件随机场的计算复杂度与窗口全连接条件随机场的计算复杂度分别为:
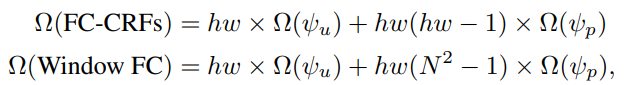
但是,这种窗口划分也会引入一个问题,就是本来应该有信息传递的相邻窗口之间失去了联系。为了解决这个问题,作者引入了swin-transformer里的shift window机制。也就是说,每次计算能量函数时,先基于正常窗口划分计算一个能量,然后将窗口平移半个窗口长度,再计算一个能量,这样就解决了窗口孤立的问题。
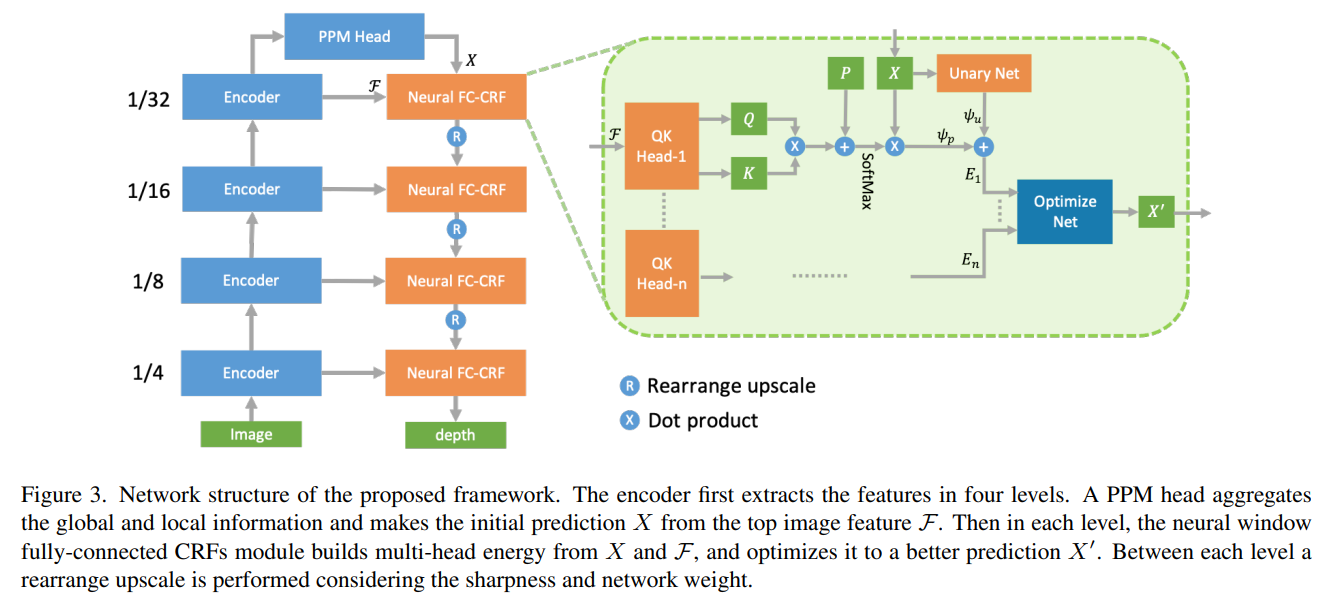
有了神经窗口全连接条件随机场,作者将它嵌入到一个bottom-up-top-down的网络中来端到端地训练。除了核心结构外,还有一个PPM Head用于聚合全局信息,Rearrange模块用于更好地上采用。详细解释可以查看论文。

3. 论文源码解析
作者模型的实现相对比较清晰,感兴趣的可以前往官方仓库详细的看一下,基本思路是根据算法框图逐一实现encoder、PPM Head以及Neural FC-CRF。
import torch
import torch.nn as nn
import torch.nn.functional as F
from .swin_transformer import SwinTransformer
from .newcrf_layers import NewCRF
from .uper_crf_head import PSP
########################################################################################################################
class NewCRFDepth(nn.Module):
"""
Depth network based on neural window FC-CRFs architecture.
"""
def __init__(self, version=None, inv_depth=False, pretrained=None,
frozen_stages=-1, min_depth=0.1, max_depth=100.0, **kwargs):
super().__init__()
self.inv_depth = inv_depth
self.with_auxiliary_head = False
self.with_neck = False
norm_cfg = dict(type='BN', requires_grad=True)
# norm_cfg = dict(type='GN', requires_grad=True, num_groups=8)
window_size = int(version[-2:])
if version[:-2] == 'base':
embed_dim = 128
depths = [2, 2, 18, 2]
num_heads = [4, 8, 16, 32]
in_channels = [128, 256, 512, 1024]
elif version[:-2] == 'large':
embed_dim = 192
depths = [2, 2, 18, 2]
num_heads = [6, 12, 24, 48]
in_channels = [192, 384, 768, 1536]
elif version[:-2] == 'tiny':
embed_dim = 96
depths = [2, 2, 6, 2]
num_heads = [3, 6, 12, 24]
in_channels = [96, 192, 384, 768]
backbone_cfg = dict(
embed_dim=embed_dim,
depths=depths,
num_heads=num_heads,
window_size=window_size,
ape=False,
drop_path_rate=0.3,
patch_norm=True,
use_checkpoint=False,
frozen_stages=frozen_stages
)
embed_dim = 512
decoder_cfg = dict(
in_channels=in_channels,
in_index=[0, 1, 2, 3],
pool_scales=(1, 2, 3, 6),
channels=embed_dim,
dropout_ratio=0.0,
num_classes=32,
norm_cfg=norm_cfg,
align_corners=False
)
self.backbone = SwinTransformer(**backbone_cfg)
v_dim = decoder_cfg['num_classes']*4
win = 7
crf_dims = [128, 256, 512, 1024]
v_dims = [64, 128, 256, embed_dim]
self.crf3 = NewCRF(input_dim=in_channels[3], embed_dim=crf_dims[3], window_size=win, v_dim=v_dims[3], num_heads=32)
self.crf2 = NewCRF(input_dim=in_channels[2], embed_dim=crf_dims[2], window_size=win, v_dim=v_dims[2], num_heads=16)
self.crf1 = NewCRF(input_dim=in_channels[1], embed_dim=crf_dims[1], window_size=win, v_dim=v_dims[1], num_heads=8)
self.crf0 = NewCRF(input_dim=in_channels[0], embed_dim=crf_dims[0], window_size=win, v_dim=v_dims[0], num_heads=4)
self.decoder = PSP(**decoder_cfg)
self.disp_head1 = DispHead(input_dim=crf_dims[0])
self.up_mode = 'bilinear'
if self.up_mode == 'mask':
self.mask_head = nn.Sequential(
nn.Conv2d(crf_dims[0], 64, 3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(64, 16*9, 1, padding=0))
self.min_depth = min_depth
self.max_depth = max_depth
self.init_weights(pretrained=pretrained)
def init_weights(self, pretrained=None):
"""Initialize the weights in backbone and heads.
Args:
pretrained (str, optional): Path to pre-trained weights.
Defaults to None.
"""
print(f'== Load encoder backbone from: {pretrained}')
self.backbone.init_weights(pretrained=pretrained)
self.decoder.init_weights()
if self.with_auxiliary_head:
if isinstance(self.auxiliary_head, nn.ModuleList):
for aux_head in self.auxiliary_head:
aux_head.init_weights()
else:
self.auxiliary_head.init_weights()
def upsample_mask(self, disp, mask):
""" Upsample disp [H/4, W/4, 1] -> [H, W, 1] using convex combination """
N, _, H, W = disp.shape
mask = mask.view(N, 1, 9, 4, 4, H, W)
mask = torch.softmax(mask, dim=2)
up_disp = F.unfold(disp, kernel_size=3, padding=1)
up_disp = up_disp.view(N, 1, 9, 1, 1, H, W)
up_disp = torch.sum(mask * up_disp, dim=2)
up_disp = up_disp.permute(0, 1, 4, 2, 5, 3)
return up_disp.reshape(N, 1, 4*H, 4*W)
def forward(self, imgs):
feats = self.backbone(imgs)
if self.with_neck:
feats = self.neck(feats)
ppm_out = self.decoder(feats)
e3 = self.crf3(feats[3], ppm_out)
e3 = nn.PixelShuffle(2)(e3)
e2 = self.crf2(feats[2], e3)
e2 = nn.PixelShuffle(2)(e2)
e1 = self.crf1(feats[1], e2)
e1 = nn.PixelShuffle(2)(e1)
e0 = self.crf0(feats[0], e1)
if self.up_mode == 'mask':
mask = self.mask_head(e0)
d1 = self.disp_head1(e0, 1)
d1 = self.upsample_mask(d1, mask)
else:
d1 = self.disp_head1(e0, 4)
depth = d1 * self.max_depth
return depth
class DispHead(nn.Module):
def __init__(self, input_dim=100):
super(DispHead, self).__init__()
# self.norm1 = nn.BatchNorm2d(input_dim)
self.conv1 = nn.Conv2d(input_dim, 1, 3, padding=1)
# self.relu = nn.ReLU(inplace=True)
self.sigmoid = nn.Sigmoid()
def forward(self, x, scale):
# x = self.relu(self.norm1(x))
x = self.sigmoid(self.conv1(x))
if scale > 1:
x = upsample(x, scale_factor=scale)
return x
class DispUnpack(nn.Module):
def __init__(self, input_dim=100, hidden_dim=128):
super(DispUnpack, self).__init__()
self.conv1 = nn.Conv2d(input_dim, hidden_dim, 3, padding=1)
self.conv2 = nn.Conv2d(hidden_dim, 16, 3, padding=1)
self.relu = nn.ReLU(inplace=True)
self.sigmoid = nn.Sigmoid()
self.pixel_shuffle = nn.PixelShuffle(4)
def forward(self, x, output_size):
x = self.relu(self.conv1(x))
x = self.sigmoid(self.conv2(x)) # [b, 16, h/4, w/4]
# x = torch.reshape(x, [x.shape[0], 1, x.shape[2]*4, x.shape[3]*4])
x = self.pixel_shuffle(x)
return x
def upsample(x, scale_factor=2, mode="bilinear", align_corners=False):
"""Upsample input tensor by a factor of 2
"""
return F.interpolate(x, scale_factor=scale_factor, mode=mode, align_corners=align_corners)
