UNetFormer: A UNet-like Transformer for Efficient Semantic Segmentation of Remote Sensing Urban Scene Imagery
0. 写在前面
这篇文章提出了基于UNet的Transformer(UNetFormer)算法,通过使用一个由CNN构成的编码器和一个由Transformer构成的解码器的混合架构,实现了高效的遥感城市场景图像语义分割,相较于CNN范式性能具有显著提升。
1. 基本信息
2. 主要内容
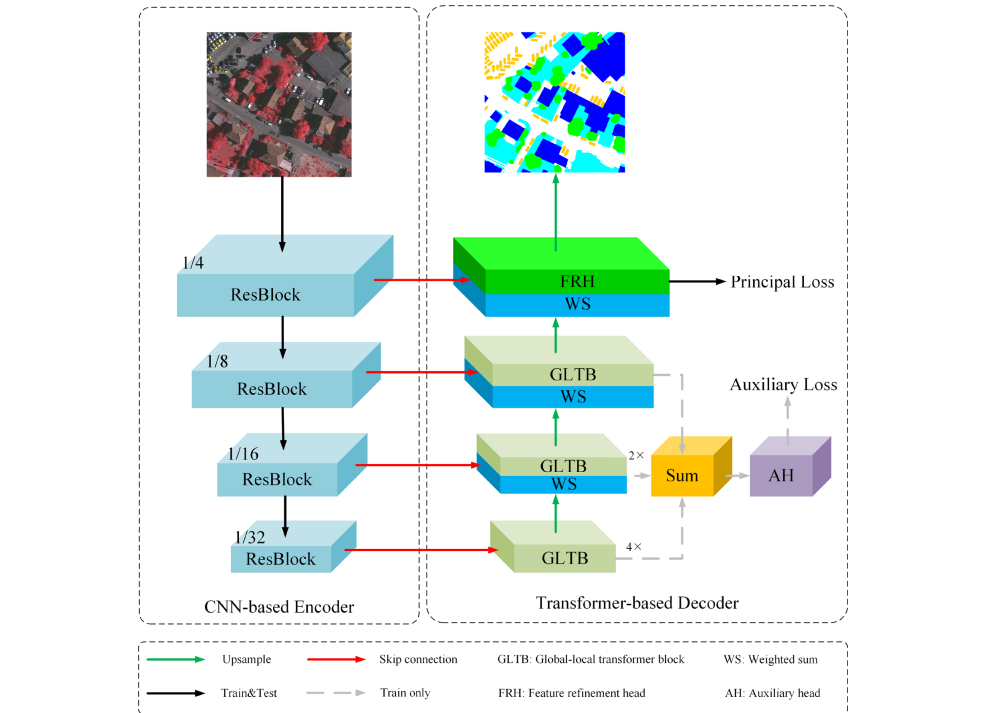
ResNet18由四个阶段的Resblocks组成,每阶段以2的比例因子对feature map进行下采样。每一阶段生成的特征图都与解码器对应的特征图进行1×1卷积(通道数为64),即跳接。具体来说,通过加权求和将残差块产生的特征与解码器的GLTB(全局-局部transfomer块)产生的特征进行聚合。加权和操作根据两个特征对分割精度的贡献有选择地对它们加权,从而学习更一般性的融合特征。加权和操作的公式为:
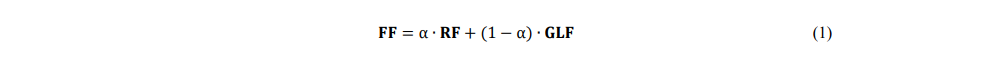
为了捕捉全局上下文,在网络末端附加单个注意力块 (Wang et al., 2018),但无法捕捉多尺度的全局特征;引入transformer作为编码器(Chen et al., 2021b),但显著增加了复杂度,并丢失了空间细节。相比之下,在提出的UNetFormer中,利用三个GLTB和一个特征细化头来构建一个轻量级的基于transformer的解码器,如上图所示。通过这种分层和轻量级的设计,解码器能够在多个尺度上捕捉全局和局部上下文,同时保持高效率。
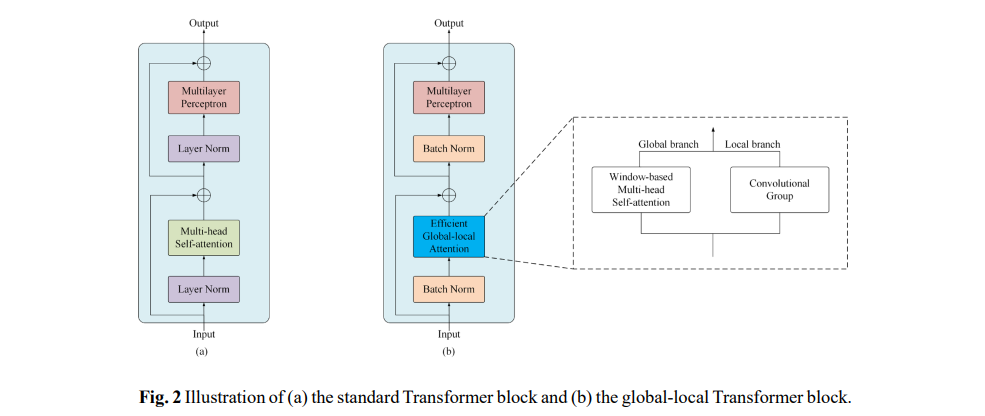
GLTB由全局-局部注意、MLP、两个batchnorm层和两个加和操作组成,全局分支中的WMHSA来自Swin提出的窗口多头自注意。
Efficient Global-local attention:局部分支是一个较浅层的结构,如下图右边蓝色框,它使用两个并行的卷积层来提取局部上下文,内核大小分别为3和1。然后在最终的求和操作之前附加两个batchnorm。
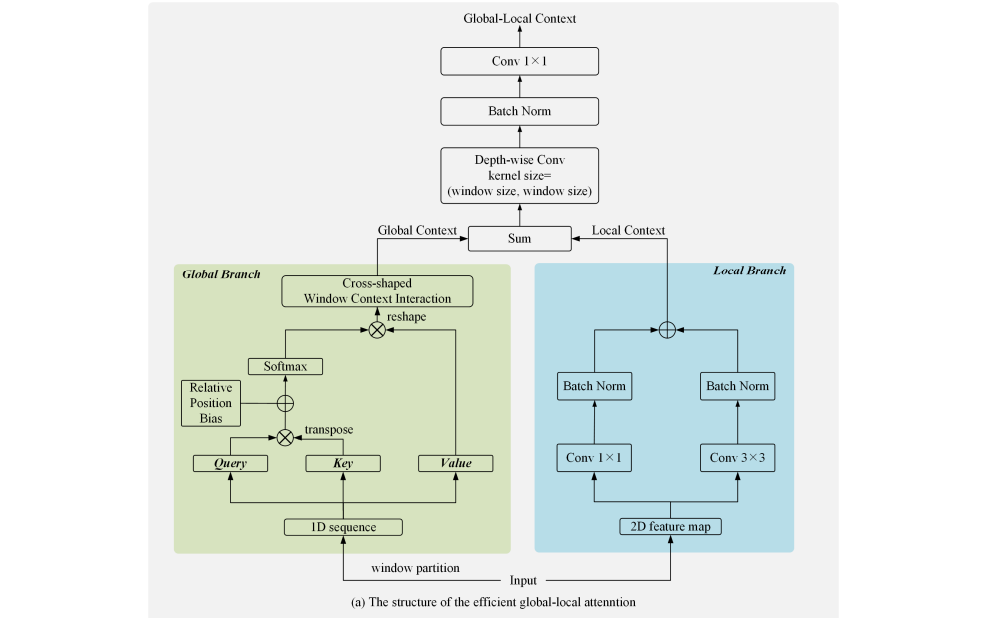
全局分支如上图左侧绿色框,首先使用一个标准1×1卷积层将输入的2D特征图的通道数扩展到三倍。然后,应用窗口划分操作将1D序列划分为Q, K, V。通道数C设为64,窗口大小w和头的数量h都设为8。
cross-shaped window context interaction module:Swin Transformer引入了一个额外的可移动Transformer块来挖掘局部窗口之间的关系。尽管捕捉跨窗口关系的能力增加了,但计算量也大幅增加。在本文中,提出了一个十字形窗口上下文交互模块来捕获跨窗口关系,具有较高的计算效率。
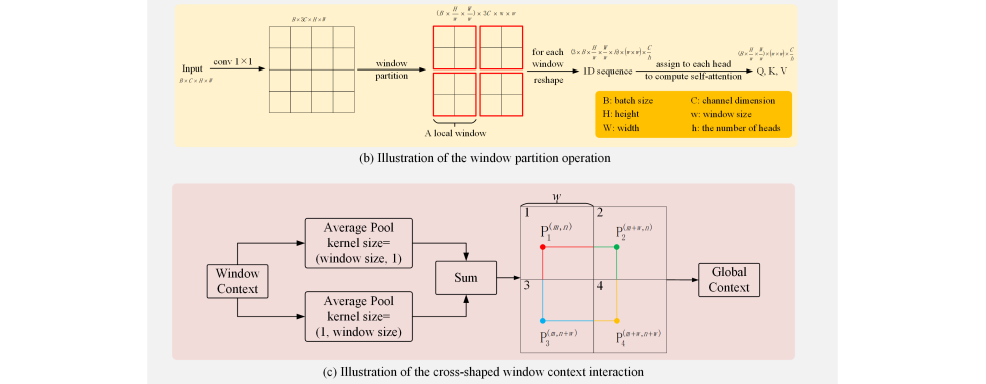
将水平平均池化层和垂直平均池化层产生的两种特征图融合,从而获取全局上下文。具体来说,水平平均池层建立了窗口之间的水平关系。对于窗口1中的任何一点 P1 ,它对窗口2中P2 的依赖可以建模为:
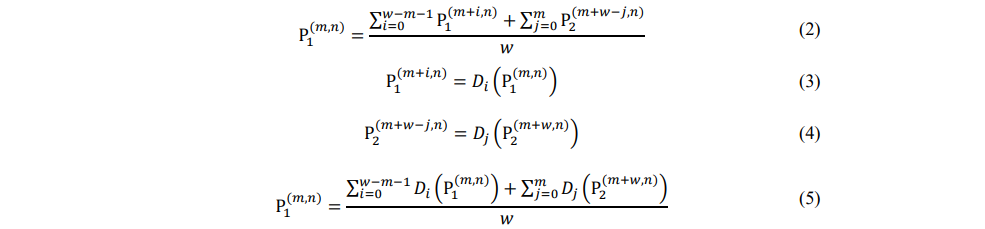
D表示自注意计算,它可以在一个局部窗口中对像素对的依赖性建模。对于M×M输入(M表示窗口的数量),通过连接更多的中间窗口,如窗口2和窗口3,任意两个窗口之间的长期依赖可以建模。因此,十字形窗口上下文交互模块可以对窗口的远程依赖关系建模,从而捕获全局上下文。
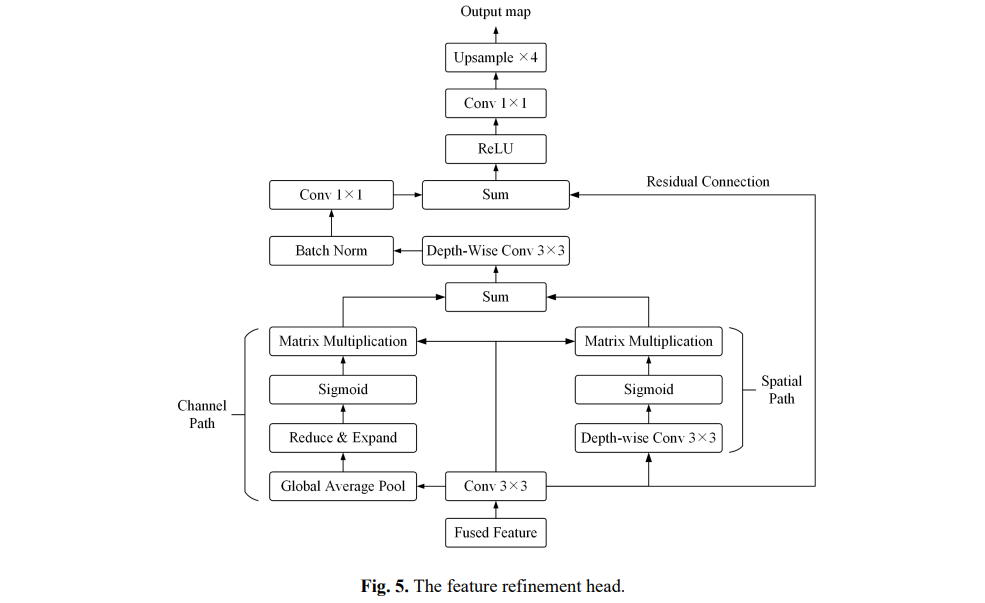
Feature refinement head (特征细化头) :第一个Resblock产生的浅层特征保留了丰富的城市场景空间细节,但缺乏语义内容;而深层的全局-局部特征提供了精确的语义信息,但空间分辨率较粗。对这两个特征直接求和,虽然速度快,但会降低分割精度。在本文中,开发了一个特征细化头FRH,以缩小两个特征之间的语义差距,进一步提高准确性。
首先对两个特征进行加权和运算,以充分利用精确的语义信息和空间细节。然后选择融合特征作为FRH的输入。其次,构建了两条路径来加强信道和空间特征表示。
损失函数:
主损失
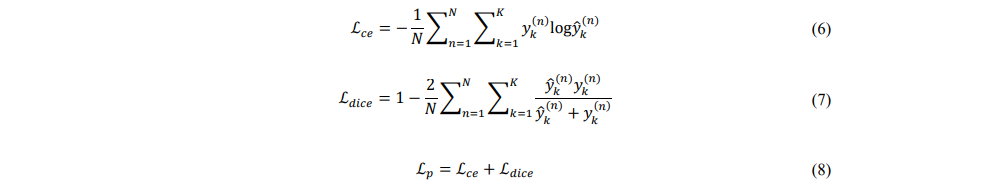
辅助损失
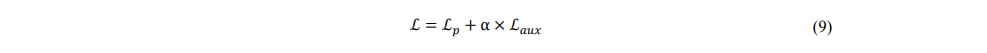
3. 源码解析
import torch
import torch.nn as nn
import torch.nn.functional as F
from einops import rearrange, repeat
from timm.models.layers import DropPath, to_2tuple, trunc_normal_
import timm
class ConvBNReLU(nn.Sequential):
def __init__(self, in_channels, out_channels, kernel_size=3, dilation=1, stride=1, norm_layer=nn.BatchNorm2d, bias=False):
super(ConvBNReLU, self).__init__(
nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, bias=bias,
dilation=dilation, stride=stride, padding=((stride - 1) + dilation * (kernel_size - 1)) // 2),
norm_layer(out_channels),
nn.ReLU6()
)
class ConvBN(nn.Sequential):
def __init__(self, in_channels, out_channels, kernel_size=3, dilation=1, stride=1, norm_layer=nn.BatchNorm2d, bias=False):
super(ConvBN, self).__init__(
nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, bias=bias,
dilation=dilation, stride=stride, padding=((stride - 1) + dilation * (kernel_size - 1)) // 2),
norm_layer(out_channels)
)
class Conv(nn.Sequential):
def __init__(self, in_channels, out_channels, kernel_size=3, dilation=1, stride=1, bias=False):
super(Conv, self).__init__(
nn.Conv2d(in_channels, out_channels, kernel_size=kernel_size, bias=bias,
dilation=dilation, stride=stride, padding=((stride - 1) + dilation * (kernel_size - 1)) // 2)
)
class SeparableConvBNReLU(nn.Sequential):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, dilation=1,
norm_layer=nn.BatchNorm2d):
super(SeparableConvBNReLU, self).__init__(
nn.Conv2d(in_channels, in_channels, kernel_size, stride=stride, dilation=dilation,
padding=((stride - 1) + dilation * (kernel_size - 1)) // 2,
groups=in_channels, bias=False),
norm_layer(out_channels),
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),
nn.ReLU6()
)
class SeparableConvBN(nn.Sequential):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, dilation=1,
norm_layer=nn.BatchNorm2d):
super(SeparableConvBN, self).__init__(
nn.Conv2d(in_channels, in_channels, kernel_size, stride=stride, dilation=dilation,
padding=((stride - 1) + dilation * (kernel_size - 1)) // 2,
groups=in_channels, bias=False),
norm_layer(out_channels),
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
)
class SeparableConv(nn.Sequential):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, dilation=1):
super(SeparableConv, self).__init__(
nn.Conv2d(in_channels, in_channels, kernel_size, stride=stride, dilation=dilation,
padding=((stride - 1) + dilation * (kernel_size - 1)) // 2,
groups=in_channels, bias=False),
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False)
)
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.ReLU6, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Conv2d(in_features, hidden_features, 1, 1, 0, bias=True)
self.act = act_layer()
self.fc2 = nn.Conv2d(hidden_features, out_features, 1, 1, 0, bias=True)
self.drop = nn.Dropout(drop, inplace=True)
def forward(self, x):
x = self.fc1(x)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class GlobalLocalAttention(nn.Module):
def __init__(self,
dim=256,
num_heads=16,
qkv_bias=False,
window_size=8,
relative_pos_embedding=True
):
super().__init__()
self.num_heads = num_heads
head_dim = dim // self.num_heads
self.scale = head_dim ** -0.5
self.ws = window_size
self.qkv = Conv(dim, 3*dim, kernel_size=1, bias=qkv_bias)
self.local1 = ConvBN(dim, dim, kernel_size=3)
self.local2 = ConvBN(dim, dim, kernel_size=1)
self.proj = SeparableConvBN(dim, dim, kernel_size=window_size)
self.attn_x = nn.AvgPool2d(kernel_size=(window_size, 1), stride=1, padding=(window_size//2 - 1, 0))
self.attn_y = nn.AvgPool2d(kernel_size=(1, window_size), stride=1, padding=(0, window_size//2 - 1))
self.relative_pos_embedding = relative_pos_embedding
if self.relative_pos_embedding:
# define a parameter table of relative position bias
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2 * window_size - 1) * (2 * window_size - 1), num_heads)) # 2*Wh-1 * 2*Ww-1, nH
# get pair-wise relative position index for each token inside the window
coords_h = torch.arange(self.ws)
coords_w = torch.arange(self.ws)
coords = torch.stack(torch.meshgrid([coords_h, coords_w])) # 2, Wh, Ww
coords_flatten = torch.flatten(coords, 1) # 2, Wh*Ww
relative_coords = coords_flatten[:, :, None] - coords_flatten[:, None, :] # 2, Wh*Ww, Wh*Ww
relative_coords = relative_coords.permute(1, 2, 0).contiguous() # Wh*Ww, Wh*Ww, 2
relative_coords[:, :, 0] += self.ws - 1 # shift to start from 0
relative_coords[:, :, 1] += self.ws - 1
relative_coords[:, :, 0] *= 2 * self.ws - 1
relative_position_index = relative_coords.sum(-1) # Wh*Ww, Wh*Ww
self.register_buffer("relative_position_index", relative_position_index)
trunc_normal_(self.relative_position_bias_table, std=.02)
def pad(self, x, ps):
_, _, H, W = x.size()
if W % ps != 0:
x = F.pad(x, (0, ps - W % ps), mode='reflect')
if H % ps != 0:
x = F.pad(x, (0, 0, 0, ps - H % ps), mode='reflect')
return x
def pad_out(self, x):
x = F.pad(x, pad=(0, 1, 0, 1), mode='reflect')
return x
def forward(self, x):
B, C, H, W = x.shape
local = self.local2(x) + self.local1(x)
x = self.pad(x, self.ws)
B, C, Hp, Wp = x.shape
qkv = self.qkv(x)
q, k, v = rearrange(qkv, 'b (qkv h d) (hh ws1) (ww ws2) -> qkv (b hh ww) h (ws1 ws2) d', h=self.num_heads,
d=C//self.num_heads, hh=Hp//self.ws, ww=Wp//self.ws, qkv=3, ws1=self.ws, ws2=self.ws)
dots = (q @ k.transpose(-2, -1)) * self.scale
if self.relative_pos_embedding:
relative_position_bias = self.relative_position_bias_table[self.relative_position_index.view(-1)].view(
self.ws * self.ws, self.ws * self.ws, -1) # Wh*Ww,Wh*Ww,nH
relative_position_bias = relative_position_bias.permute(2, 0, 1).contiguous() # nH, Wh*Ww, Wh*Ww
dots += relative_position_bias.unsqueeze(0)
attn = dots.softmax(dim=-1)
attn = attn @ v
attn = rearrange(attn, '(b hh ww) h (ws1 ws2) d -> b (h d) (hh ws1) (ww ws2)', h=self.num_heads,
d=C//self.num_heads, hh=Hp//self.ws, ww=Wp//self.ws, ws1=self.ws, ws2=self.ws)
attn = attn[:, :, :H, :W]
out = self.attn_x(F.pad(attn, pad=(0, 0, 0, 1), mode='reflect')) + \
self.attn_y(F.pad(attn, pad=(0, 1, 0, 0), mode='reflect'))
out = out + local
out = self.pad_out(out)
out = self.proj(out)
# print(out.size())
out = out[:, :, :H, :W]
return out
class Block(nn.Module):
def __init__(self, dim=256, num_heads=16, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.ReLU6, norm_layer=nn.BatchNorm2d, window_size=8):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = GlobalLocalAttention(dim, num_heads=num_heads, qkv_bias=qkv_bias, window_size=window_size)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, out_features=dim, act_layer=act_layer, drop=drop)
self.norm2 = norm_layer(dim)
def forward(self, x):
x = x + self.drop_path(self.attn(self.norm1(x)))
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class WF(nn.Module):
def __init__(self, in_channels=128, decode_channels=128, eps=1e-8):
super(WF, self).__init__()
self.pre_conv = Conv(in_channels, decode_channels, kernel_size=1)
self.weights = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.eps = eps
self.post_conv = ConvBNReLU(decode_channels, decode_channels, kernel_size=3)
def forward(self, x, res):
x = F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=False)
weights = nn.ReLU()(self.weights)
fuse_weights = weights / (torch.sum(weights, dim=0) + self.eps)
x = fuse_weights[0] * self.pre_conv(res) + fuse_weights[1] * x
x = self.post_conv(x)
return x
class FeatureRefinementHead(nn.Module):
def __init__(self, in_channels=64, decode_channels=64):
super().__init__()
self.pre_conv = Conv(in_channels, decode_channels, kernel_size=1)
self.weights = nn.Parameter(torch.ones(2, dtype=torch.float32), requires_grad=True)
self.eps = 1e-8
self.post_conv = ConvBNReLU(decode_channels, decode_channels, kernel_size=3)
self.pa = nn.Sequential(nn.Conv2d(decode_channels, decode_channels, kernel_size=3, padding=1, groups=decode_channels),
nn.Sigmoid())
self.ca = nn.Sequential(nn.AdaptiveAvgPool2d(1),
Conv(decode_channels, decode_channels//16, kernel_size=1),
nn.ReLU6(),
Conv(decode_channels//16, decode_channels, kernel_size=1),
nn.Sigmoid())
self.shortcut = ConvBN(decode_channels, decode_channels, kernel_size=1)
self.proj = SeparableConvBN(decode_channels, decode_channels, kernel_size=3)
self.act = nn.ReLU6()
def forward(self, x, res):
x = F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=False)
weights = nn.ReLU()(self.weights)
fuse_weights = weights / (torch.sum(weights, dim=0) + self.eps)
x = fuse_weights[0] * self.pre_conv(res) + fuse_weights[1] * x
x = self.post_conv(x)
shortcut = self.shortcut(x)
pa = self.pa(x) * x
ca = self.ca(x) * x
x = pa + ca
x = self.proj(x) + shortcut
x = self.act(x)
return x
class AuxHead(nn.Module):
def __init__(self, in_channels=64, num_classes=8):
super().__init__()
self.conv = ConvBNReLU(in_channels, in_channels)
self.drop = nn.Dropout(0.1)
self.conv_out = Conv(in_channels, num_classes, kernel_size=1)
def forward(self, x, h, w):
feat = self.conv(x)
feat = self.drop(feat)
feat = self.conv_out(feat)
feat = F.interpolate(feat, size=(h, w), mode='bilinear', align_corners=False)
return feat
class Decoder(nn.Module):
def __init__(self,
encoder_channels=(64, 128, 256, 512),
decode_channels=64,
dropout=0.1,
window_size=8,
num_classes=6):
super(Decoder, self).__init__()
self.pre_conv = ConvBN(encoder_channels[-1], decode_channels, kernel_size=1)
self.b4 = Block(dim=decode_channels, num_heads=8, window_size=window_size)
self.b3 = Block(dim=decode_channels, num_heads=8, window_size=window_size)
self.p3 = WF(encoder_channels[-2], decode_channels)
self.b2 = Block(dim=decode_channels, num_heads=8, window_size=window_size)
self.p2 = WF(encoder_channels[-3], decode_channels)
if self.training:
self.up4 = nn.UpsamplingBilinear2d(scale_factor=4)
self.up3 = nn.UpsamplingBilinear2d(scale_factor=2)
self.aux_head = AuxHead(decode_channels, num_classes)
self.p1 = FeatureRefinementHead(encoder_channels[-4], decode_channels)
self.segmentation_head = nn.Sequential(ConvBNReLU(decode_channels, decode_channels),
nn.Dropout2d(p=dropout, inplace=True),
Conv(decode_channels, num_classes, kernel_size=1))
self.init_weight()
def forward(self, res1, res2, res3, res4, h, w):
if self.training:
x = self.b4(self.pre_conv(res4))
h4 = self.up4(x)
x = self.p3(x, res3)
x = self.b3(x)
h3 = self.up3(x)
x = self.p2(x, res2)
x = self.b2(x)
h2 = x
x = self.p1(x, res1)
x = self.segmentation_head(x)
x = F.interpolate(x, size=(h, w), mode='bilinear', align_corners=False)
ah = h4 + h3 + h2
ah = self.aux_head(ah, h, w)
return x, ah
else:
x = self.b4(self.pre_conv(res4))
x = self.p3(x, res3)
x = self.b3(x)
x = self.p2(x, res2)
x = self.b2(x)
x = self.p1(x, res1)
x = self.segmentation_head(x)
x = F.interpolate(x, size=(h, w), mode='bilinear', align_corners=False)
return x
def init_weight(self):
for m in self.children():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, a=1)
if m.bias is not None:
nn.init.constant_(m.bias, 0)
class UNetFormer(nn.Module):
def __init__(self,
decode_channels=64,
dropout=0.1,
backbone_name='swsl_resnet18',
pretrained=True,
window_size=8,
num_classes=6
):
super().__init__()
self.backbone = timm.create_model(backbone_name, features_only=True, output_stride=32,
out_indices=(1, 2, 3, 4), pretrained=pretrained)
encoder_channels = self.backbone.feature_info.channels()
self.decoder = Decoder(encoder_channels, decode_channels, dropout, window_size, num_classes)
def forward(self, x):
h, w = x.size()[-2:]
res1, res2, res3, res4 = self.backbone(x)
if self.training:
x, ah = self.decoder(res1, res2, res3, res4, h, w)
return x, ah
else:
x = self.decoder(res1, res2, res3, res4, h, w)
return x
