EMP-SSL: Towards Self-Supervised Learning in One Training Epoch
0. 写在前面
这篇文章是马毅和LeCun团队的新作,主要目的是解决自监督学习训练不高效的问题。笔者认为这篇文章值得学习借鉴的是自监督学习的图像增强技巧以及其带来的表征学习能力。
1. 论文基本信息
2. 论文主要内容
过去几年,无监督和自监督学习(SSL)取得了巨大进步,通过SSL学习得到的表征在分类性能上甚至赶上了有监督学习,在某些情况下甚至还能超过有监督学习,这一趋势也为视觉任务的大规模数据驱动无监督学习提供了可能。
虽然自监督学习的实验性能惊人,但大多数自监督学习方法都是相当「低效」的,通常需要数百个训练epoch才能完全收敛。
最近,马毅教授、图灵奖得主Yann LeCun团队发布了一种新的自监督学习方法Extreme-Multi-Patch Self-Supervised-Learning(EMP-SSL),证明了高效自监督学习的关键是增加每个图像实例中的图像块数量。
与其他 SSL 方法类似,EMP-SSL也是从图像的增强视图(augmented views)中获得联合嵌入,其中增强视图是固定大小的图像块(image patch)
这类方法有两个目标:同一图像的两个不同增强图像的表征应该更接近;表征空间不应该 collapsed trivial space,即必须保留数据的重要几何或随机结构。
之前的研究主要探索了各种策略和不同的启发式方法来实现这两个特性,并取得了越来越好的性能,其成功主要源于对图像块共现的学习。
为了让图像块共现的学习更有效率,研究人员在EMP-SSL中将自监督学习中的图像块数量增加到了极限(extreme)。
首先,对于输入的图像,先通过随机裁剪(可重叠)切分成n个固定大小的图像块,然后使用标准的数据增强技术对图像块进行增强。
对每个增强的图像块,通过两个网络分别获得获取嵌入(embedding)和投影(projection),其中嵌入网络是一个比较深的网络(如ResNet-18),投影网络更小,只有两个全连接层,二者共同组成编码器。
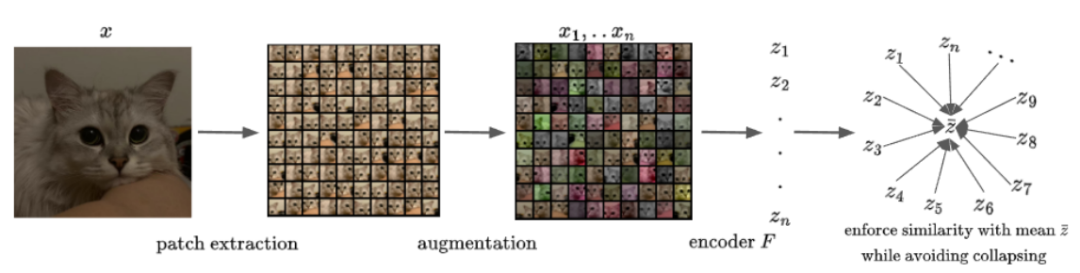
在训练期间,模型采用Total Coding Rate(TCR)正则化技术来避免表征崩溃。
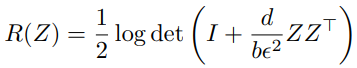
研究人员也希望来自同一图像的不同图像块的表征是不变的,即在表示空间中应该尽可能接近,所以要尽量缩小增强图像的表征与同一图像中所有增强图像块的平均表征之间的距离,所以训练目标为:
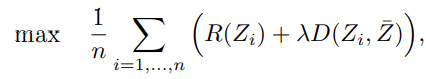
其中Z代表不同增强图像块的表征平均值,D为距离函数(余弦相似度),即D的值越大,二者越相似。
这个目标函数可以看作是最大速率下降(maximal rate reduction)的一个变体,也可以看作是基于协方差的 SSL 方法的广义版本,将n设置为2就是常见的2-view自监督学习方法,也可以将n设的更大,以提高图像块贡献的学习速度。

实验结果
对比其他最先进的自监督学习方法,可以看到,即便EMP-SSL只看过一次数据集,也能收敛到接近完全收敛的SOTA性能。结果表明,该方法不仅在提高当前 SSL 方法的收敛性方面具有巨大潜力,而且在计算机视觉的其他领域,如在线学习、增量学习和机器人学习中,也具有巨大潜力。
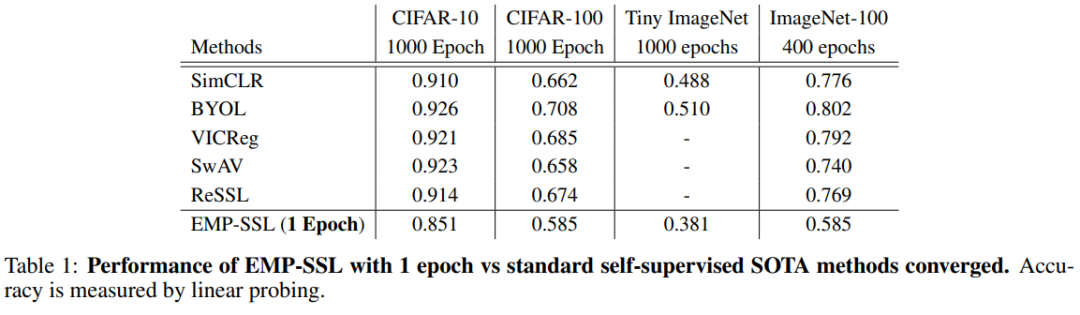
在标准数据集中,包括CIFAR-10、CIFAR-100、Tiny ImageNet 和 ImageNet-100,研究人员验证了所提目标函数在收敛速度方面的效率。
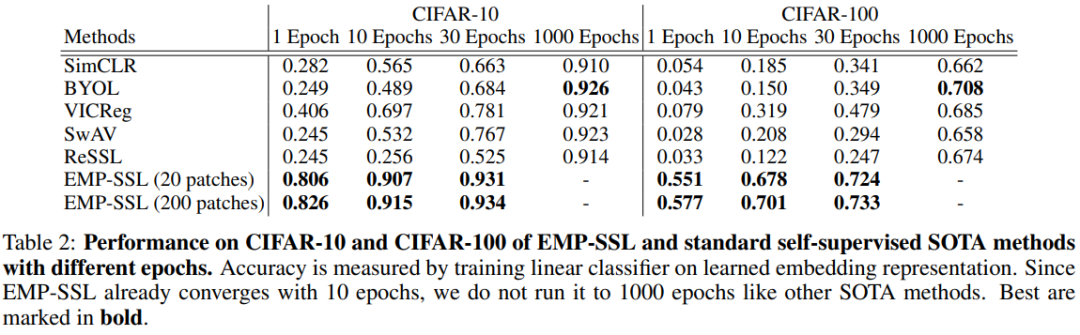
可以看到,EMP-SSL仅在一个epoch的训练之后,就在 20 个图像块的设置下实现了 80.6% 的准确率,在 200 个图像块设置下可以实现82.6%的准确率。
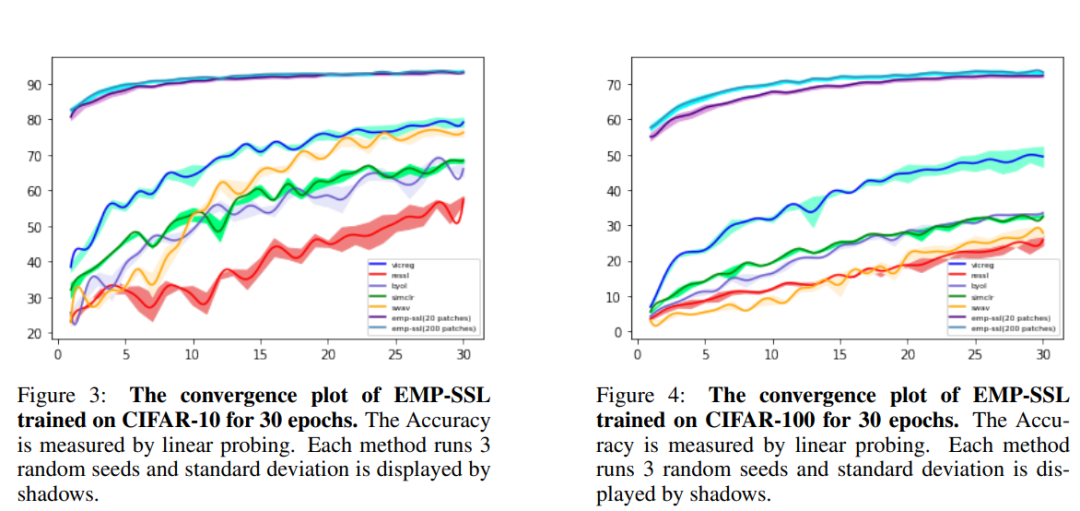
在10个epoch后,EMP-SSL就已经收敛到超过90%,也是CIFAR-10数据集上最先进的自监督学习方法;而30个 epochs 时,EMP-SSL 的准确率更是超过了当前所有方法,达到了 93% 以上。
研究人员使用 t-SNE maps的结果来证明,尽管只训练几个epoch,EMP-SSL 已经学到了有意义的表征。在CIFAR-10训练集上学到的表征图中,EMP-SSL 使用 200 个图像块训练了 10 个 epochs,其他 SOTA 方法则训练了 1000 个 epochs,其中每个颜色代表一个不同的类别。可以看到,EMP-SSL 为不同类别学习到的表征分离得更好,并且更结构化;与其他 SOTA 方法相比,EMP-SSL学习到的特征显示出更精细的低维结构。最令人惊叹的是,所有这些结构都是在短短 10 个epoch的训练中学到的!


