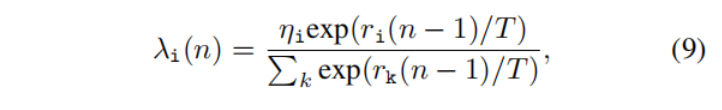Multi-interactive Feature Learning and a Full-time Multi-modality Benchmark for Image Fusion and Segmentation
0. 写在前面
早期的多模态图像融合工作只注重提升融合后图像的视觉效果,缺乏对下游检测、分割等任务的考虑,在这篇文章中,作者提出了一种用于图像融合和分割的多交互特征学习架构,并利用双任务相关性来提高融合和分割两个子任务的性能。笔者认为这篇文章主要有两个点值得参考和学习,第一个是为图像融合和分割任务设计的网络架构,第二个是用于网络训练的动态权重平衡学习策略。
1. 论文基本信息
2. 论文主要内容
SegMiF 模型架构设计
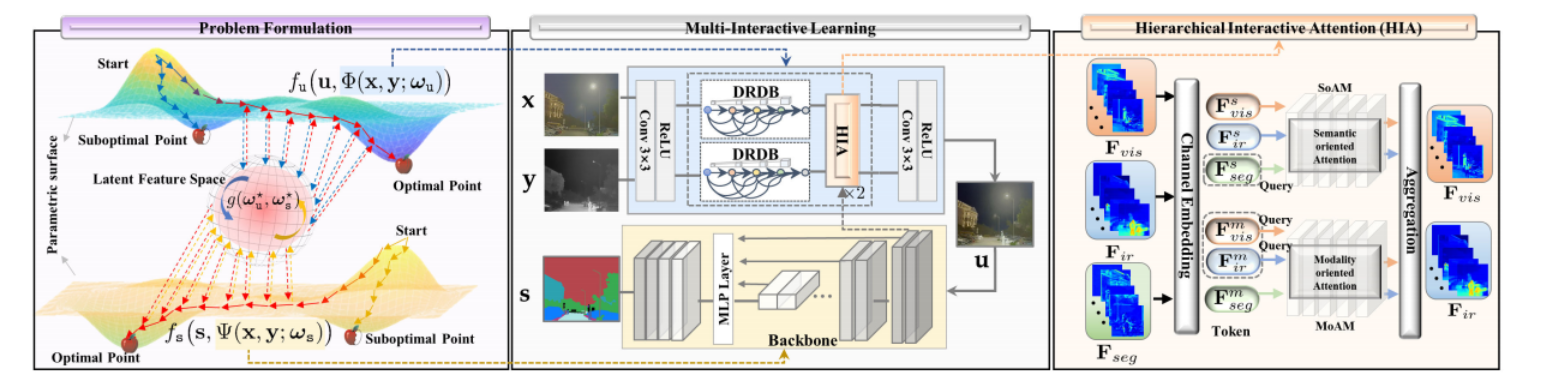
之前的方法只设计图像融合或分割网络,只能在一个任务上取得突出的效果。为了生成具有视觉吸引力的融合图像和精确的场景分割结果,作者将这两个任务共同表示为同一个目标,如下公式所示:
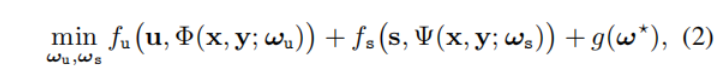
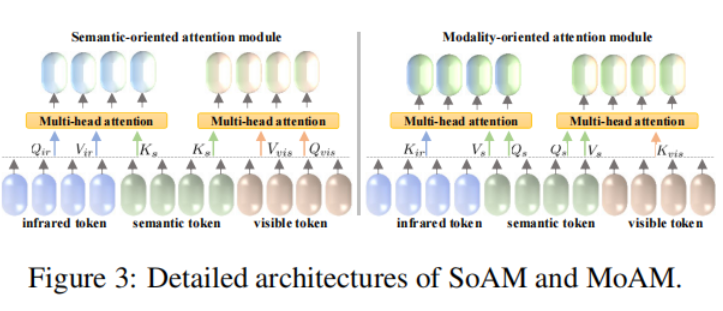
如图所示,作者提出的SegMiF采用级联原理设计,由图像融合和分割自网络组成。为了充分实现语义信息的共享,作者这里提出了层次交互注意模块HIA来实现高级知识信息的融合。如下图所示,HIA主要由SoAM和MoAM组成,而SoAM和MoAM则主要是通过将来自红外图像的特征与可见光图像的特征以及分割结果对应的特征作为自注意力机制中的k、Q和V来分别实现不同模态特征以及不同任务特征的交互融合。
动态权重平衡学习策略
在图像融合阶段,作者引入了动态加权因子lambda1和Lambda2来快速测量任务相关损失的重要性,在本文中任务为融合任务与分割任务。作者观察到特定任务的平衡可以从收敛率中得出。从直觉上来说,如果损失的值不能进一步下降,网络可以得到相应的最优权值。如果收敛率下降得很快,作者认为就应该更加注意这项任务。如果将ri 视为第i个任务的收敛率,则其收敛率可以用以下公式表示。
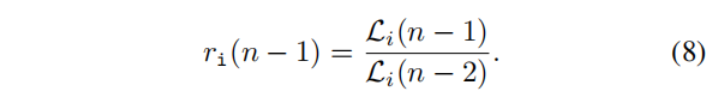
如此,第i个任务的动态权重因子的计算可以用以下公式表示,其中T是控制两个任务敏感性的温度系数。: